Machine Learning Engineer Test - Problem 1
%matplotlib inline
from keras.preprocessing.text import Tokenizer
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from sklearn.model_selection import StratifiedKFold
from sklearn.linear_model import LinearRegression, LogisticRegression, PassiveAggressiveClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn import linear_model
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report, accuracy_score
from sklearn.svm import SVC
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Activation, Embedding, Flatten, Convolution1D, MaxPooling1D, Input, LSTM
from keras.preprocessing import sequence
from keras.regularizers import l2
from keras.layers import Merge
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import cross_val_score
1. Understanding and preprocessing the data
I understand this task is similar to a sentiment analysis task. The provided training data contains sentences that are already tokenized. Each line contains two parts: First part is sentiment label of the sentence (0 or 1), the second part is as list of tokens (words).
I first analyse and pre-process the data:
train_small_file = "data/training-data-small.txt"
train_small_df = pd.read_csv(train_small_file, sep='\t', names=["Label", "Text"])
train_small_df.head()
| Label | Text | |
|---|---|---|
| 0 | 0 | X773579,Y2640,Y2072,Z4,Z15 |
| 1 | 0 | X166074297,X123474229,X147204623,X51578397,X23... |
| 2 | 1 | X374616379,X773579,X344420902,Y1940,Y1705,Z4,Z... |
| 3 | 0 | X103413307,X37875376,X62716332,X277692318,X344... |
| 4 | 0 | X123474229,X551805107,X62716661,Y2307,Y2,Y1222... |
train_small_df.Label.hist()
plt.title("Training Label Distribution")
<matplotlib.text.Text at 0x7effe3a63d68>
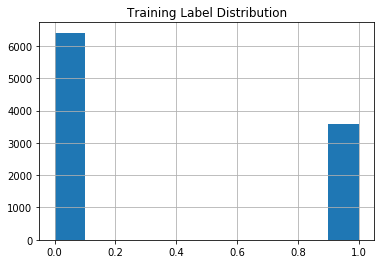
I think that the dataset is quite imbalanced.
Next I analyse length of texts.
train_small_df_text_len = train_small_df.Text.str.split(",").apply(len)
train_small_df_text_len.describe()
count 10000.000000
mean 26.251200
std 17.841097
min 2.000000
25% 12.000000
50% 22.000000
75% 36.000000
max 100.000000
Name: Text, dtype: float64
The average text is 26 words long. longest text has 100 words.
X, y = np.array(train_small_df.Text), np.array(train_small_df.Label)
Next, I want to transform each sentence into a sequence of intergers (which are indices of the sentence’s tokens in the whole vocaburary of tokens from the dataset). I can write a Tokenizer to do this, but here I use a Tokenizer from Keras. When transforming sentences to sequences, I consider vocaburay from both training set and test set.
Load test data:
test_small_file = "data/test-data-small.txt"
test_small_df = pd.read_csv(test_small_file, sep=" ", names=["Text"])
test_small_df_text_len = test_small_df.Text.str.split(",").apply(len)
X_test = np.array(test_small_df.Text)
X_total = np.concatenate((X, X_test))
tknzr = Tokenizer(lower=False, split=',')
tknzr.fit_on_texts(X_total)
XS = tknzr.texts_to_sequences(X)
XS_test = tknzr.texts_to_sequences(X_test)
The sequences have different length, I need to truncate and pad the sequences so that there are all the same length (longest length of sentences in the dataset) for modeling.
max_len = train_small_df_text_len.max() if train_small_df_text_len.max() > test_small_df_text_len.max() else test_small_df_text_len.max()
XS = sequence.pad_sequences(XS, maxlen=max_len)
XS_test = sequence.pad_sequences(XS_test, maxlen=max_len)
XS.shape, XS_test.shape
((10000, 102), (100000, 102))
Let’s get the vocaburary size of the dataset:
vocab_size = len(tknzr.word_counts)
vocab_size
127
I have transformed the dataset to sequence dataset of interger with 102 features.
Now the problem becomes the sequence classification problem.
2. Modeling
I will do experiment with some different models. First I create a function so that I can evaluate the models with cross validation.
def cv_evaluate_classifier(clasifier, X, y, n_splits=5, **kwargs):
kfold = StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=0)
clf = clasifier(**kwargs)
results = cross_val_score(clf, X, y, cv=kfold, scoring='accuracy')
print('\nModel average accuracy: {:.2f}'.format(results.mean()))
def cv_evaluate_nn_model(build_fn, X, y, nb_epoch=5, n_splits=5, batch_size=32, **kwargs):
kfold = StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=0)
model = KerasClassifier(build_fn=build_fn, nb_epoch=nb_epoch, batch_size=batch_size, verbose=1)
results = cross_val_score(model, X, y, cv=kfold)
print('\nModel average accuracy: {:.2f}'.format(results.mean()))
I start with LogisticRegression model:
def create_lr_model():
lr_model = LogisticRegression()
return lr_model
cv_evaluate_classifier(create_lr_model, XS, y)
Model average accuracy: 0.66
I try with an SVM model:
def create_svm_model():
svm_model = SVC(C=10, kernel='linear')
return svm_model
cv_evaluate_classifier(create_svm_model, XS, y)
This takes so long time in my envoriment, so I skip it.
Experiment with Deep Learning models
I do experiment with some NN models to see weather deep learning works for this dataset. First I try with a simple single hidden layer NN.
def single_nn_model():
model = Sequential([
Embedding(vocab_size+1, 32, input_length=max_len),
Flatten(),
Dense(100, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
cv_evaluate_nn_model(single_nn_model, XS, y, nb_epoch=2)
Epoch 1/2
8000/8000 [==============================] - 0s - loss: 0.5665 - acc: 0.7061
Epoch 2/2
8000/8000 [==============================] - 0s - loss: 0.4828 - acc: 0.7659
1984/2000 [============================>.] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 0s - loss: 0.5670 - acc: 0.6979
Epoch 2/2
8000/8000 [==============================] - 0s - loss: 0.4893 - acc: 0.7644
32/2000 [..............................] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 0s - loss: 0.5632 - acc: 0.7047
Epoch 2/2
8000/8000 [==============================] - 0s - loss: 0.4838 - acc: 0.7724
2000/2000 [==============================] - 0s
Epoch 1/2
8000/8000 [==============================] - 0s - loss: 0.5699 - acc: 0.7009
Epoch 2/2
8000/8000 [==============================] - 0s - loss: 0.4887 - acc: 0.7634
32/2000 [..............................] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 0s - loss: 0.5646 - acc: 0.7053
Epoch 2/2
8000/8000 [==============================] - 0s - loss: 0.4811 - acc: 0.7707
1888/2000 [===========================>..] - ETA: 0s
Model average accuracy: 0.77
We can get average accuracy of 0.77 with this simple NN model. This is much better than the LogisticRegression model.
Next, I try with more complex NN - a single convolution layer with max pooling
def create_conv_nn():
conv = Sequential([
Embedding(vocab_size+1, 32, input_length=max_len, dropout=0.2),
Dropout(0.2),
Convolution1D(64, 3, border_mode='same', activation='relu'),
Dropout(0.2),
MaxPooling1D(),
Flatten(),
Dense(100, activation='relu'),
Dropout(0.7),
Dense(1, activation='sigmoid')
])
conv.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return conv
cv_evaluate_nn_model(create_conv_nn, XS, y, nb_epoch=2)
Epoch 1/2
8000/8000 [==============================] - 0s - loss: 0.5867 - acc: 0.6816
Epoch 2/2
8000/8000 [==============================] - 0s - loss: 0.5256 - acc: 0.7406
2000/2000 [==============================] - 0s
Epoch 1/2
8000/8000 [==============================] - 0s - loss: 0.5876 - acc: 0.6801
Epoch 2/2
8000/8000 [==============================] - 0s - loss: 0.5327 - acc: 0.7344
1280/2000 [==================>...........] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 0s - loss: 0.5776 - acc: 0.6911
Epoch 2/2
8000/8000 [==============================] - 0s - loss: 0.5216 - acc: 0.7466
1280/2000 [==================>...........] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 0s - loss: 0.5766 - acc: 0.6934
Epoch 2/2
8000/8000 [==============================] - 0s - loss: 0.5340 - acc: 0.7435
1280/2000 [==================>...........] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 0s - loss: 0.5752 - acc: 0.6943
Epoch 2/2
8000/8000 [==============================] - 0s - loss: 0.5289 - acc: 0.7421
1280/2000 [==================>...........] - ETA: 0s
Model average accuracy: 0.76
The accuracy seems not improving.
Above I created a CNN layer with single kernel size (3). Here I try another model with multi kernel sizes of the CNN layer.
def create_multi_cnn_model():
graph_in = Input((vocab_size+1, 32))
convs = []
for ker_size in range(3,6):
x = Convolution1D(64, ker_size, border_mode='same', activation='relu')(graph_in)
x = MaxPooling1D()(x)
x = Flatten()(x)
convs.append(x)
out = Merge(mode='concat')(convs)
graph = Model(graph_in, out)
model = Sequential([
Embedding(vocab_size+1, 32, input_length=max_len, dropout=0.2),
Dropout(0.2),
graph,
Dropout(0.5),
Dense(100, activation='relu'),
Dropout(0.7),
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
cv_evaluate_nn_model(create_multi_cnn_model, XS, y, nb_epoch=2)
Epoch 1/2
8000/8000 [==============================] - 1s - loss: 0.5743 - acc: 0.6950
Epoch 2/2
8000/8000 [==============================] - 1s - loss: 0.5323 - acc: 0.7363
1856/2000 [==========================>...] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 1s - loss: 0.5769 - acc: 0.6940
Epoch 2/2
8000/8000 [==============================] - 1s - loss: 0.5335 - acc: 0.7400
1856/2000 [==========================>...] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 1s - loss: 0.5790 - acc: 0.6886
Epoch 2/2
8000/8000 [==============================] - 1s - loss: 0.5245 - acc: 0.7436
1856/2000 [==========================>...] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 1s - loss: 0.5815 - acc: 0.6924
Epoch 2/2
8000/8000 [==============================] - 1s - loss: 0.5301 - acc: 0.7421
1856/2000 [==========================>...] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 1s - loss: 0.5828 - acc: 0.6913
Epoch 2/2
8000/8000 [==============================] - 1s - loss: 0.5297 - acc: 0.7455
1824/2000 [==========================>...] - ETA: 0s
Model average accuracy: 0.77
I try with a RNN model - LSTM
def create_lstm_model():
model = Sequential([
Embedding(vocab_size+1, 32, input_length=max_len, mask_zero=True, W_regularizer=l2(1e-6), dropout=0.2),
LSTM(100, consume_less='gpu'),
Dense(1, activation='sigmoid')])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
cv_evaluate_nn_model(create_lstm_model, XS, y, nb_epoch=2)
Epoch 1/2
8000/8000 [==============================] - 12s - loss: 0.5752 - acc: 0.6937 - ETA: 9s - loss: 0.6456 - acc: 0.6377 - ETA: 1s - loss: 0.5863 - acc: 0.6831
Epoch 2/2
8000/8000 [==============================] - 12s - loss: 0.5136 - acc: 0.7543 - ETA: 7s - loss: 0.5081 - acc: 0.7554 - ETA: 7s - loss: 0.5097 - acc: 0.7552 - ETA: 6s - loss: 0.5106 - acc: 0.7536
2000/2000 [==============================] - 1s
Epoch 1/2
8000/8000 [==============================] - 12s - loss: 0.5607 - acc: 0.7127 - ETA: 10s - loss: 0.6344 - acc: 0.6329
Epoch 2/2
8000/8000 [==============================] - 12s - loss: 0.5129 - acc: 0.7499 - ETA: 10s - loss: 0.5289 - acc: 0.7454
2000/2000 [==============================] - 0s
Epoch 1/2
8000/8000 [==============================] - 12s - loss: 0.5555 - acc: 0.7177 - ETA: 9s - loss: 0.6355 - acc: 0.6305 - ETA: 6s - loss: 0.6000 - acc: 0.6724
Epoch 2/2
8000/8000 [==============================] - 12s - loss: 0.5151 - acc: 0.7522
1952/2000 [============================>.] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 12s - loss: 0.5584 - acc: 0.7146 - ETA: 7s - loss: 0.5957 - acc: 0.6714 - ETA: 2s - loss: 0.5681 - acc: 0.7100 - ETA: 2s - loss: 0.5665 - acc: 0.7108
Epoch 2/2
8000/8000 [==============================] - 12s - loss: 0.5121 - acc: 0.7501 - ETA: 9s - loss: 0.5208 - acc: 0.7489 - ETA: 9s - loss: 0.5163 - acc: 0.7500
1920/2000 [===========================>..] - ETA: 0sEpoch 1/2
8000/8000 [==============================] - 12s - loss: 0.5589 - acc: 0.7106 - ETA: 15s - loss: 0.6879 - acc: 0.6375 - ETA: 7s - loss: 0.5948 - acc: 0.6739
Epoch 2/2
8000/8000 [==============================] - 12s - loss: 0.5069 - acc: 0.7592
1952/2000 [============================>.] - ETA: 0s
Model average accuracy: 0.76
After evaluating several models, i think that with this small dataset, trainning on the complex model (NN) may not have a big impact on the performance. For the sake of training speed, I choose the small NN (single hidden layer neural network) to make a submission:
sub_model = single_nn_model()
Traing the model on full dataset (I train with only 3 epoches, with more epoches the model will have high overfiting):
sub_model.fit(XS, y, batch_size=32, nb_epoch=3)
Epoch 1/3
10000/10000 [==============================] - 0s - loss: 0.5536 - acc: 0.7101
Epoch 2/3
10000/10000 [==============================] - 0s - loss: 0.4818 - acc: 0.7732
Epoch 3/3
10000/10000 [==============================] - 0s - loss: 0.4557 - acc: 0.7856
<keras.callbacks.History at 0x7effb46f3b70>
y_preds = sub_model.predict(XS_test)
y_preds[-3]
array([ 0.72289443], dtype=float32)
submission_file_name = 'subm/problem_1_submission.csv'
np.savetxt(submission_file_name, y_preds, fmt='%.5f')
from IPython.display import FileLink
FileLink(submission_file_name)