Machine Learning Engineer Test - Problem 2
%matplotlib inline
from keras.preprocessing.text import Tokenizer
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from sklearn.model_selection import StratifiedKFold
from sklearn.linear_model import LinearRegression, LogisticRegression, PassiveAggressiveClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn import linear_model
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report, accuracy_score
from sklearn.svm import SVC
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Activation, Embedding, Flatten, Conv1D, MaxPooling1D, Input, LSTM, SpatialDropout1D
from keras.preprocessing import sequence
from keras.regularizers import l2
from keras.layers import Merge
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import cross_val_score
import bcolz
I. Understanding and preprocessing the data
Since the large dataset is significant larger than the small dataset. The preprocessing process used in problem may not work for this large data. First, I analysis the data to have a suitable preprocessing.
train_large_file = "data/training-data-large.txt"
test_large_file = "data/test-data-large.txt"
train_large_df = pd.read_csv(train_large_file, sep='\t', names=["Label", "Text"])
train_large_df.head()
| Label | Text | |
|---|---|---|
| 0 | 0 | X191305328,X374456501,Y275963,Y285847,Z39 |
| 1 | 1 | X354083841,X139888513,X542912533,Y252401,Z38 |
| 2 | 1 | X62718521,X50527000,X459131054,X344420902,X263... |
| 3 | 1 | X600952733,X344420902,X551774608,Y3229,Y3396,Y... |
| 4 | 0 | X225006700,X51578397,X174205309,X569638406,X29... |
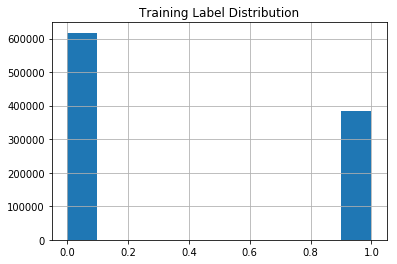
train_large_df.Label.hist()
plt.title("Training Label Distribution")
<matplotlib.text.Text at 0x7f3d99b4e518>
Next I analyse length of texts.
train_large_df_text_len = train_large_df.Text.str.split(",").apply(len)
train_large_df_text_len.describe(percentiles=[0.5, 0.8, 0.99])
count 1000000.000000
mean 71.308072
std 78.989477
min 2.000000
50% 46.000000
80% 119.000000
99% 356.000000
max 5042.000000
Name: Text, dtype: float64
The average text is 71 words long. longest text has 5042 words, which is too long. The 356 words long sentence would cover 99% of the data set.
Let’s load the test dataset:
test_large_df = pd.read_csv(test_large_file, sep=" ", names=["Text"])
test_large_df_text_len = test_large_df.Text.str.split(",").apply(len)
test_large_df_text_len.describe(percentiles=[0.5, 0.8, 0.99])
count 100000.000000
mean 80.157140
std 80.372452
min 2.000000
50% 56.000000
80% 129.000000
99% 365.010000
max 2014.000000
Name: Text, dtype: float64
The average text in the test set is 80 words long. longest text has 2014 words. The 365 words long sentence would cover 99% of the data set.
From this analysis, I limit the maximum length for preprocessing to 400:
max_len = 400
Transfer sentence to sequence
X, y = np.array(train_large_df.Text), np.array(train_large_df.Label)
X_test = np.array(test_large_df.Text)
Let’s see how big the vocabulary size of the dataset:
X_total = np.concatenate((X, X_test))
tknzr = Tokenizer(lower=False, split=',')
tknzr.fit_on_texts(X_total)
vocab_size = len(tknzr.word_counts)
print(vocab_size)
67311
It is too costly to transfer all 67311 words into sequence. I limit maximum number of words to be included. Words (tokens) are ranked by how often they occur (in the dataset) and only the most frequent words are kept. This maximum number of words is number of features for the modeling.
max_features = 20000
tknzr = Tokenizer(num_words=max_features, lower=False, split=',')
tknzr.fit_on_texts(X_total)
XS = tknzr.texts_to_sequences(X)
XS_test = tknzr.texts_to_sequences(X_test)
XS = sequence.pad_sequences(XS, maxlen=max_len)
XS_test = sequence.pad_sequences(XS_test, maxlen=max_len)
XS.shape, XS_test.shape
((1000000, 400), (100000, 400))
I save these sequence data, for quickly load later.
def save_array(fname, arr):
c=bcolz.carray(arr, rootdir=fname, mode='w')
c.flush()
def load_array(fname):
return bcolz.open(fname)[:]
save_array('train_large.dat', XS)
save_array('test_large.dat', XS_test)
save_array('y_train.dat', y)
XS = load_array('train_large.dat')
y = load_array('y_train.dat')
XS_test = load_array('test_large.dat')
I have transformed the dataset to sequence dataset of interger with 400 features.
Now the problem becomes the sequence classification problem. With this large data, I focus on using Deep Learning models.
2. Modeling
For this large data doing cross-validation would be very time consuming. So here I split the data to training set and validation set to test the models.
X_train, X_test, y_train, y_test = train_test_split(XS, y, test_size=0.2, random_state=0)
A single hidden layer neural network
def single_nn_model():
model = Sequential([
Embedding(max_features, 32, input_length=max_len),
Flatten(),
Dense(100, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
single_nn_model = single_nn_model()
single_nn_model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=2, batch_size=32)
Train on 800000 samples, validate on 200000 samples
Epoch 1/2
800000/800000 [==============================] - 277s - loss: 0.2546 - acc: 0.8941 - val_loss: 0.2377 - val_acc: 0.9022
Epoch 2/2
800000/800000 [==============================] - 277s - loss: 0.2325 - acc: 0.9053 - val_loss: 0.2344 - val_acc: 0.9031
<keras.callbacks.History at 0x7fdcd8612d50>
With just 2 epoches of training, this simple NN gains about 0.90 accuracy in the validation set. I continue trying with more complex NN.
A single convolution layer with max pooling
def create_conv_nn():
conv = Sequential([
Embedding(max_features, 32, input_length=max_len),
SpatialDropout1D(0.2),
Conv1D(64, 3, padding='same', activation='relu'),
Dropout(0.2),
MaxPooling1D(),
Flatten(),
Dense(100, activation='relu'),
Dropout(0.7),
Dense(1, activation='sigmoid')
])
conv.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return conv
conv_nn_model = create_conv_nn()
conv_nn_model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=2, batch_size=32)
Train on 800000 samples, validate on 200000 samples
Epoch 1/2
800000/800000 [==============================] - 705s - loss: 0.2654 - acc: 0.8910 - val_loss: 0.2335 - val_acc: 0.9042
Epoch 2/2
800000/800000 [==============================] - 706s - loss: 0.2456 - acc: 0.9023 - val_loss: 0.2342 - val_acc: 0.9040
<keras.callbacks.History at 0x7fdccf6319d0>
conv_nn_model.optimizer.lr = 1e-3
conv_nn_model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=4, batch_size=32)
Train on 800000 samples, validate on 200000 samples
Epoch 1/4
800000/800000 [==============================] - 707s - loss: 0.2424 - acc: 0.9039 - val_loss: 0.2333 - val_acc: 0.9043
Epoch 2/4
800000/800000 [==============================] - 703s - loss: 0.2400 - acc: 0.9051 - val_loss: 0.2382 - val_acc: 0.9038
Epoch 3/4
800000/800000 [==============================] - 704s - loss: 0.2386 - acc: 0.9055 - val_loss: 0.2348 - val_acc: 0.9055
Epoch 4/4
800000/800000 [==============================] - 704s - loss: 0.2377 - acc: 0.9061 - val_loss: 0.2396 - val_acc: 0.9038
<keras.callbacks.History at 0x7fdccf63a110>
This model also gets 0.90 accuracy even with more epoches.
A Multi-size CNN model
Above I created a CNN layer with single kernel size (3). Here I try another model with multi kernel size of CNN layer.
def create_multi_cnn_model():
graph_in = Input((max_features, 32))
convs = []
for ker_size in range(3,6):
x = Conv1D(64, ker_size, padding='same', activation='relu')(graph_in)
x = MaxPooling1D()(x)
x = Flatten()(x)
convs.append(x)
out = Merge(mode='concat')(convs)
graph = Model(graph_in, out)
model = Sequential([
Embedding(max_features, 32, input_length=max_len),
SpatialDropout1D(0.2),
graph,
Dropout(0.5),
Dense(100, activation='relu'),
Dropout(0.7),
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
multi_cnn_model = create_multi_cnn_model()
/home/ubuntu/anaconda2/lib/python2.7/site-packages/ipykernel/__main__.py:9: UserWarning: The `Merge` layer is deprecated and will be removed after 08/2017. Use instead layers from `keras.layers.merge`, e.g. `add`, `concatenate`, etc.
multi_cnn_model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=32)
Train on 800000 samples, validate on 200000 samples
Epoch 1/10
800000/800000 [==============================] - 1457s - loss: 0.2692 - acc: 0.8898 - val_loss: 0.2376 - val_acc: 0.9036
Epoch 2/10
800000/800000 [==============================] - 1454s - loss: 0.2520 - acc: 0.9000 - val_loss: 0.2650 - val_acc: 0.8896
Epoch 3/10
800000/800000 [==============================] - 1454s - loss: 0.2503 - acc: 0.9005 - val_loss: 0.2364 - val_acc: 0.9035
Epoch 4/10
800000/800000 [==============================] - 1454s - loss: 0.2500 - acc: 0.9007 - val_loss: 0.2406 - val_acc: 0.9011
Epoch 5/10
800000/800000 [==============================] - 1452s - loss: 0.2497 - acc: 0.9007 - val_loss: 0.2400 - val_acc: 0.9041
Epoch 6/10
800000/800000 [==============================] - 1452s - loss: 0.2499 - acc: 0.9011 - val_loss: 0.2344 - val_acc: 0.9052
Epoch 7/10
800000/800000 [==============================] - 1451s - loss: 0.2503 - acc: 0.9008 - val_loss: 0.2377 - val_acc: 0.9020
Epoch 8/10
800000/800000 [==============================] - 1451s - loss: 0.2507 - acc: 0.9009 - val_loss: 0.2352 - val_acc: 0.9052
Epoch 9/10
800000/800000 [==============================] - 1451s - loss: 0.2514 - acc: 0.9005 - val_loss: 0.2391 - val_acc: 0.9050
Epoch 10/10
800000/800000 [==============================] - 1451s - loss: 0.2516 - acc: 0.9002 - val_loss: 0.2367 - val_acc: 0.9052
<keras.callbacks.History at 0x7ff1f631fcd0>
multi_cnn_model.save_weights('multi_cnn.h5')
This model also give us about 0.90 accuracy even I train with 10 epoches. But this model seems quite generalize, after 10 epoches the model is still note overfiting. However the training time for each epoch is 1452s on AWS EC2 p2.xlarge instance (Tesla K80 GPU)
A RNN model - LSTM
def create_lstm_model():
model = Sequential([
Embedding(max_features, 128, input_length=max_len, mask_zero=True, embeddings_regularizer=l2(1e-6)),
SpatialDropout1D(0.2),
LSTM(128, implementation=2),
Dense(1, activation='sigmoid')])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
lstm_model = create_lstm_model()
lstm_model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=32)
Train on 800000 samples, validate on 200000 samples
Epoch 1/10
800000/800000 [==============================] - 7833s - loss: 0.2647 - acc: 0.8887 - val_loss: 0.2354 - val_acc: 0.9036
Epoch 2/10
800000/800000 [==============================] - 7847s - loss: 0.2332 - acc: 0.9055 - val_loss: 0.2303 - val_acc: 0.9066
Epoch 3/10
800000/800000 [==============================] - 7825s - loss: 0.2282 - acc: 0.9084 - val_loss: 0.2312 - val_acc: 0.9073
Epoch 4/10
800000/800000 [==============================] - 7822s - loss: 0.2253 - acc: 0.9102 - val_loss: 0.2282 - val_acc: 0.9088
Epoch 5/10
800000/800000 [==============================] - 7829s - loss: 0.2228 - acc: 0.9118 - val_loss: 0.2287 - val_acc: 0.9088
Epoch 6/10
800000/800000 [==============================] - 7835s - loss: 0.2212 - acc: 0.9130 - val_loss: 0.2295 - val_acc: 0.9091
Epoch 7/10
800000/800000 [==============================] - 7830s - loss: 0.2196 - acc: 0.9140 - val_loss: 0.2304 - val_acc: 0.9098
Epoch 8/10
800000/800000 [==============================] - 7834s - loss: 0.2188 - acc: 0.9148 - val_loss: 0.2312 - val_acc: 0.9091
Epoch 9/10
800000/800000 [==============================] - 7846s - loss: 0.2182 - acc: 0.9157 - val_loss: 0.2315 - val_acc: 0.9096
Epoch 10/10
800000/800000 [==============================] - 7834s - loss: 0.2175 - acc: 0.9161 - val_loss: 0.2326 - val_acc: 0.9096
<keras.callbacks.History at 0x7ff1e3f84b10>
lstm_model.save_weights('lstm.h5')
This model gets slightly better accuracy (0.91). However the training time for each epoch is big (~7834s).
Since I already trained the LSTM model and it seems to get a good accuracy, I use this model to make a submission for the test:
y_preds = lstm_model.predict(XS_test)
submission_file_name = 'subm/problem_2_submission.csv'
np.savetxt(submission_file_name, y_preds, fmt='%.5f')
from IPython.display import FileLink
FileLink(submission_file_name)